Database Design and Naming Conventions
Introduction
I have looked around a lot and decided that the majority of "standards" for databases don't make sense, so I thought I would document mine.
Background
Looking around at the standards on the internet I see that there are suggestions
like, use the prefix tbl for a table name, and col for column
names, use the table name for the primary column name, they are silly. It
gets worse when people start prefixing column names. The worst one I saw was
cusCustomerNotes for a string in their customer table. So I am going
to put forward my philosophy, and explain each one.
Natural Joins Are Evil
I start here, because my next point will be argued to no end if I don't. One of the most nonsensical arguments I hear is that columns should be uniquely named, that way your tool "knows" the proper join without you having to do an explicit join. Thus the tool, like enterprise manager or in the case of Oracle the SQL Execution engine, will explicitly or implicitly create the join for you.
If you don't know what a natural join is, it is the simple description is "you can be lazy and not write your join because the database knows what you mean". So SQL like the following actually works (doesn't even complain in Oracle).
SELECT person.*,card.* from person, card
The obvious problem here is that you have NO idea what is being joined on social
security number, person, who knows... Furthermore, you have no idea, if it
is supposed to be an inner join (as a natural join is), or if it is a cross join.
A Cross join joins all the rows from both tables.
A secondary problem is that different Database Systems, will treat the statement differently, some treat it as a cross join others treat it as a natural join.
It is my experience that all joins should be explicit, and laid out as joins. The following clearly indicates what is intended.
SELECT person.*, card.*
FROM person
INNER JOIN card
ON card.person_id = person.person_id
If I had designed the tables it would look like the following instead. (Note the id column in the person table is now just id rather than person_id), so a natural join won't work. However tools like Enterprise Manager will recognize the foreign key relationship. This is assuming that one exists, and it absolutely needs to if you want you to make sure your data integrity.
SELECT person.*, card.*
FROM person
INNER JOIN card
ON card.person_id = person.idI dislike implicit joins in the where clause for one very simple reason, you then to miss joins, thus you end up with natural and cross joins. On complex queries like the following you could very easily make a mistake.
select country.countryname, state.statename, county.countyname, city.cityname
FROM country, state, county, city
WHERE state.country=country.country and city.county=county.county
At very minimum in this example state and county are a natural join or cross join depending on whether or not there is a matching column name, but we don't know, so who knows what data this will return.
In my opinion it is better to be specific so that the compiler knows what you what rather than making it guess.
Reuse Column Names
Why would I ever want to make unique names for every table, for simple things, if
a column is the unique row ID, then it should probably called ID, if
it is for a description it should probably be called Description.
This way when accessing the table or using it for something like a dropdown list
it will always be the same SQL. Consistency is the name of the game, if you
always name the column representing the name "Name" it will be much easier
to deal with than colcustblCustomerNameString. If we stop and think about
it, we already know the table name, so why include it in the name of the column?
Furthermore, Databases aren't there only to hold data, some program is out there
using it, so more modern program might even be able to use mapping tools called Object
Relational Mappers, naming consistency helps everything.
Every Table Gets a Row Indentifier
There is nothing worse than trying to enforce database constraints when the tables are joined against multiple columns on a for a single entity when the parent row has a compound key. Here is our state, county and city example when things get crazy..
SELECT Country.CountryName, State.StateName, County.CountyName
FROM Country
INNER JOIN State
ON State.CountryName = Country.CountryName
INNER JOIN County
ON County.StateName = State.StateName
AND County.CountryName = State.CountryName
AND County.CountryName = Country.CountryName
As you can see that gets carried away in a big hurry, and admittedly this is bad example for a select statement, since all the information is in the county table. However, most databases don't support a multiple column foriegn key, so imagine what happens when someone types the wrong country name when entering a county. By each and every table having a unique row identifier, allows you to reference that row for integrity with foreign keys and simplifying those joins in your SQL.
SELECT Country.Name as Country, State.Name as State, County.Name as County
FROM Country
INNER JOIN State
ON State.Country_ID = Country.ID
INNER JOIN County
ON County.State_ID = State.ID
As you can see it simplifies the SQL as well. Before I leave this subject, I'd like to touch on Guids vs other keys.
Unique Identifiers and Primary Keys
There is a lot of arguments about whether or not Guids make useful primary keys. I think the point is being missed, Guids are supposed to be unique identifiers, this is not to say that they should be used for the primary key, because they clustering (organization of the rows in the actual file system) would be meaningless, and thus performance will degrade horribly. These Guids should used as a unique row identifier, and in some cases they are required for synchronization technologies.
A very common complaint about guids is that they are hard to remember. Yes that is true, which is why they should never be used as the primary key, the thing that makes the row unique should be the primary key, ideally human meaningful data so humans can look at it. But when enforcing constraints at the database level especially in relationships it is nice to know that you can NOT put the wrong data into a column. Take a look at the following entity relationship diagram
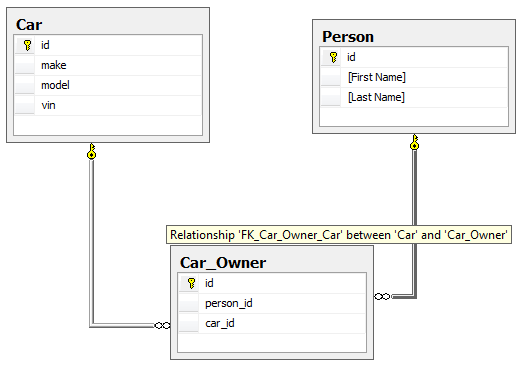
Looking at this we see that foreign key relationships have been put on the tables, so as far as the database can tell a row will be valid as long as a row with the correct number exists in the parent tables. But if we realize that they are just integers, a bug in a program, a cut and paste error, or typo in a stored procedure could flip that data around. Inserting the numbers from the person table into the "car_id" column and the numbers from the car table into the "person_id" column. Depending on the number of rows in each table it may be a very long time before the error is caught, and then all the data has to be re-entered. Thus, just because you have a foreign key, that alone it doesn't guarantee valid data. However, if the ID columns are indeed guids, the chances of such mistakes are minimized to the point of virtual non-existence.
In other words this SQL is much more likely to be wrong and not caught
INSERT INTO Car_Owner (person_id, car_id) VALUES (3, 5)
Than this one is
INSERT INTO Car_Owner (person_id, car_id)
VALUES ('{E1D56D43-4FCA-44B1-8D16-BF7F106D0A6D}',
'{BCFB7934-6FB2-4AC1-96BC-1D8D46C7067D}')
Primary Keys should be on the unique data for the row
Two part thought here, first, Guids aren't meaningful to humans, you should not need to know the guid for day to day use of your data. They are for data integrity, not for use by people. Second, when looking for data, the database needs to be able to find that data easily. So you should never make a person tables unique key, the guid, you would make it on something unique about them, perhaps their social security number, with a secondary non-unique index on their last, middle and first names. The problem with using the name as the primary key, is names like John Smith aren't unique, however that will likely be a common search item, hence the non-unique index.
Columns that Reference Other Tables
When a table needs to reference and existing row in another table, it should follow a few rules.
- Such columns should only reference the row id column
- The reference should be enforced with a foreign key constraint
- It should include the table name
Touching on each point individually I will start with the first one. A table
should contain unique data, that is the reason for it's existence. There are
2 rows in the table with the exact same data, you have a problem, however the row
might be associating 2 other tables, like my Car_Owner table above.
If I have a table that now needs to reference that table, I don't want to keep
that relationship in another place, and I want to make sure that relationship exists.
So rather than keeping 2 columns, in my new table, I would simply keep the ID column
from Car_Owner, or as another example, I wouldn't want to keep County, State,
and Country, columns in my City table, when I can keep the single column of County_ID
in the City table.
For the second point, it's fairly simple, we tell the database to ensure that the data we are referencing actually exists.
Lastly including the table name ensures consistency. I know that if I have
a column named Person_ID that it is going to be the ID column from the Person table.
Relationship Tables Should Only Join 2 Tables
All too often people will try to force multiple relationships into a single table. For example look at the following image
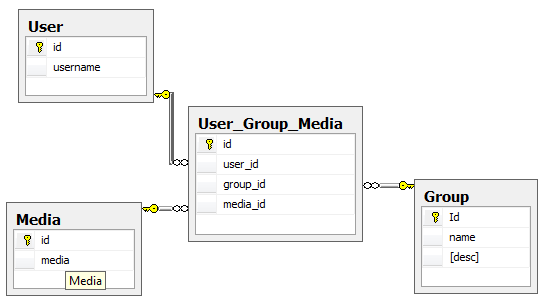
From this relationship you can't tell how this relationship is supposed to be,
or that the other relationships, like a user belonging to one or multiple groups
actually exist. If the relationship where defined 2 at a time you could tell
if this table where associating medias to groups of users, or groups of media to users,
or what. The associations would also be guarenteed to exist before making the next
association. For example, in a car lease contract for a corporation, you would
want to make sure the contract and corporation exist, before you start assigning
cars to it.
Use Schema/Namespaces to Seperate like Named Objects
In the old
days, or when using weak databases, you would have to resort to naming your
object differently to be able to tell apart a State (a plot of land) from a State (where in a workflow your process is). So you would end up naming one
WorkFlowState and the other State, which is fine, but modern databases can
partition the 2 objects into separate blocks. Some databases call these
blocks "schemas", some call them "namespaces", while MySQL seems to think they are separate
databases. For the most part, the partitioning of these objects into
namespaces is conceptually no different than making objects in your program use
different namespaces. Your query will have to be specific, but it doesn't
prevent the object from being used.
Fear of Keywords
As you can tell I am not afraid of using words for column and table names that might be keywords. Most
modern databases give you some what to handle escaping keywords so you can use
them as things like column names. SQL92, which should have been adhered to
by ALL database now, specifies the double quote ( " ) character to do this.
Microsoft SQL Server uses square brackets ( [] ) to do it, and if
QUOTED_IDENTIFIER ON is specified, it allows double quotes, MySQL uses, of all things, the accent grave (`) .
For all you .NET coders, the DataProviders give you the characters if you know where to look.
Make full use of your database
Strongly Type your Data
Just like in programming, there are different types to do different things, use the proper type for the job. In other words strongly type your data.
- Use a
booleanorbit, to hold true/false values - don't use character fields to hold numbers
- make sure number fields have constraints for valid values
- only use
char/ncharfields when the data is truly fixed length
Just like in programming, these types not only help you keep the data available efficiently, but they help enforce the integrity of the data. Using fixed length character fields to hold variable length data is a personal peeve of mine. Because if the data isn't as long as the field the database pads it, requiring the programming to trim the padding everywhere.
Use Cascades, Triggers and Constraints
Cascades make sure that when you delete or update a row, rows that depend on it are deleted or changed as well.
Triggers can help make sure that calculations get run, when data is updated.
Constraints on fields can make sure of things like "this field must be a positive number", The thing to be aware of though is use of this to enforce "magic values", IE "this field must be a 'P', 'Q' or 'Z'" that is a sure sign that it really should be a foreign key to a table, so you can display it to the user.
Avoid overloading fields
Don't use a field to indicate one thing, say price, in one circumstance, and another thing, say discount percentage, in another. It makes writing both SQL and code against the database nightmarish.
Bringing It all Together
As you can tell, when I make table that represent relationships between multiple
tables, my best thought has been to name the table the tables that it is joining, separated by an underscore. Even in databases (or database settings) that support differentiating by case only, I don't want confusion between multi-word table
names and relationship table names, for example I don't want User_Groups to
be confused with UserGroups.
These guidelines mean you can normalize your data in a meaningful way, ensuring data integrity.
At this point someone is going to whine about the performance of normalized databases versus non-normalized databases, and someone else will join in about how guids are big and slow. Think about this though, the data in your database is likely of paramount importance, are you willing to sacrifice a small amount of speed to be guaranteed the integrity of your data, or are you willing to go down the route of super high performance and possibly have your data trashed. If you really stop and think about it, normalization can enhance performance, by allowing updates to every user in a group by simply changing the group record, rather than having to change every user row as you would in a non-normalized database.
Using consistent naming means I can save time in writing SQL, because I know what things will be named, and joins will be easy and consistently fast. Furthermore, if a well written Object Relational Mapper is used, I might be able to take advantage of inheritance in the programming model.
So as a final example here is a normalized database example using Country, State, County, and City, and relationship tables. It may be over-normalized, but, it means there will only be 1 record per name, things like populations, zip codes etc. could be added to the relationship records where they are meaningful. However, this is a nice academic example but it isn't worthwhile for a business example, because of Consolidated City Counties, cities like St. Louis Missouri, which does not exist within any county, and because of Washington D.C. which doesn't exist within any state. However, it does account for a city named Springfield in every state, with no data duplication.
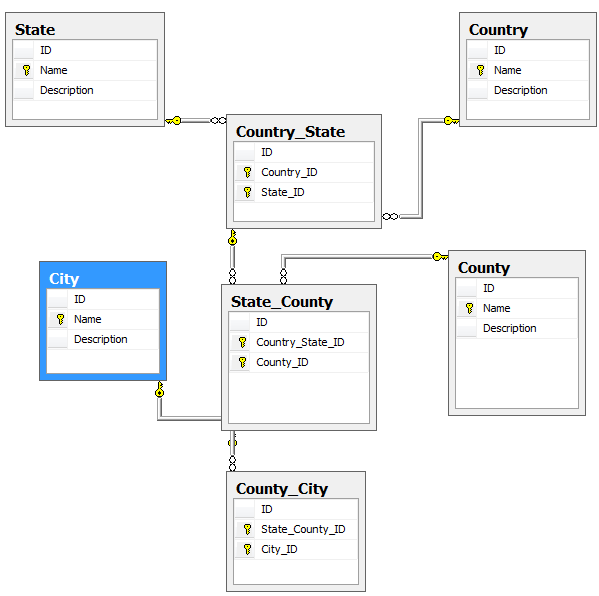
SELECT
Country.Name as Country, State.Name AS State, County.Name AS County, City.Name AS City
FROM Country
INNER JOIN Country_State
ON Country.ID = Country_State.Country_ID
INNER JOIN State
ON Country_State.State_ID = State.ID
INNER JOIN State_County
ON Country_State.ID = State_County.Country_State_ID
INNER JOIN County
ON State_County.County_ID = County.ID
INNER JOIN County_City
ON State_County.ID = County_City.State_County_ID
INNER JOIN City
ON County_City.City_ID = City.ID
Gotchas
Like any other ideas on designing databases, there are things that could cause problems. People depending on natural joins is a big one, and I addressed that issue above. The only real problem I have run into, is trying to use EntityFramework with this design. While I haven't tried version 4 with this design, however version 3.5 has a very serious problem even when using SQL Server. EntityFramework doesn't seem to pick up the relationships for foreign keys unless they are against the primary key, this bug forced me to create a clustered unique constraint on a Name column and make my ID column a primary key.
Things for Next Time
I haven't touched on several items, like naming views or stored procedures. Nor did I touch on writing SQL too much, I tried to keep it to just the SQL necessary to explain the choices I have made. Remember to let me know what you think of my articles by voting.
发表评论
 RoyalCBD.com[89.28.10.*]2020/9/29 1:16:13#1
RoyalCBD.com[89.28.10.*]2020/9/29 1:16:13#15mHw3P Perfectly written written content , thankyou for selective information.