How to Read and Write ODF/ODS Files (OpenDocument Spreadsheets)
Introduction
The OpenDocument Format (ODF) is an XML-based file format for representing electronic documents such as spreadsheets, charts, presentations and word processing documents. The standard was developed by the OASIS (Organization for the Advancement of Structured Information Standards), and it is a free and open format.
The OpenDocument format is used in free software and in proprietary software. Originally, the format was implemented by the OpenOffice.org office suite and, with Office 2007 SP2, Microsoft also supports ODF subset.
This article will explain the basics of ODF format, and specifically its implementation in spreadsheet applications (OpenOffice.org Calc and Microsoft Office Excel 2007 SP2). Presented is a demo application which writes/reads tabular data to/from .ods files. The application is written in C# using Visual Studio 2010. Created .ods files can be opened using Excel 2007 SP2 or greater and OpenOffice.org Calc.
ODF Format
OpenDocument format supports document representation:
- As a single XML document
- As a collection of several subdocuments within a package
Office applications use the second approach, so we will explain in detail.
Every ODF file is a collection of several subdocuments within a package (ZIP file), each of which stores part of the complete document. Each subdocument stores a particular aspect of the document. For example, one subdocument contains the style information and another subdocument contains the content of the document.
This approach has the following benefits:
- You don't need to process the entire file in order to extract specific data.
- Images and multimedia are now encoded in native format, not as text streams.
- Files are smaller as a result of compression and native multimedia storage.
There are four subdocuments in the package that contain file's data:
- content.xml - Document content and automatic styles used in the content
- styles.xml - Styles used in the document content and automatic styles used in the styles themselves
- meta.xml - Document meta information, such as the author or the time of the last save action
- settings.xml - Application-specific settings, such as the window size or printer information
Besides them, in the package, there can be many other subdocuments like document thumbnail, images, etc.
In order to read the data from an ODF file, you need to:
- Open package as a ZIP archive
- Find parts that contain data you want to read
- Read parts you are interested in
On the other side, if you want to create a new ODF file, you need to:
- Create/get all necessary parts
- Package everything into a ZIP file with appropriate extension
Spreadsheet Documents
Spreadsheet document files are the subset of ODF files. Spreadsheet files have .ods file extensions.
The content (sheets) is stored in content.xml subdocument.

As we can see in Picture 1, sheets are stored as XML elements. They contain column and row definitions, rows contain cells and so on... In the picture is data from one specific document, but from this we can see the basic structure of content.xml file (you can also download the full ODF specification).
Implementation
Our demo is Windows Presentation Foundation application (picture 2) written in C# using Visual Studio 2010.
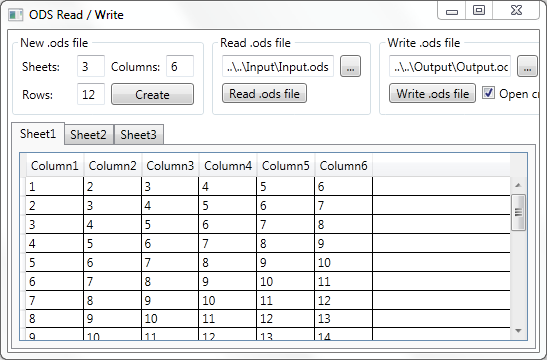
The application can:
- create a new Spreadsheet document.
- read an existing Spreadsheet document.
- write a created Spreadsheet document.
Creating New Document and Underlying Model of Application
Internally, spreadsheet document is stored as DataSet. Each sheet is represented with DataTable, sheet's row with DataRow, and sheet's column with DataColumn. So, to create a new document, we have to create a new DataSet, with DataTables. Each DataTable has a number of rows and columns that conforms to our needs.
To show data from our DataSet (and to allow editing that data) the application dynamically creates tabs with DataGridViews (that are connected to our DataTables).
Through the interface, a user can read, write, edit data and add new rows to the Spreadsheet document.
As application, basically, transforms Spreadsheet document to / from DataSet, it can also be used as a reference for Excel to DataSet export / import scenarios.
Zip Component and XML Parser
Although classes from System.IO.Packaging namespace (.NET 3.0) provide a way to read and write ZIP files, they require a different format of ZIP file. Because of that, our demo uses the open source component called DotNetZip.
Using ZIP component we can extract files, get subdocument, replace (or add) subdocuments that we want and save that file as .ods file (which is a ZIP file).
For processing documents, we have used XmlDocument because it offers an easy way to reach parts that we want. Note that, if performance is crucial for you, you should use XmlTextReader and XmlTextWriter. That solution needs more work (and code), but provides better performance.
Reading Spreadsheet Document
To read a document, we follow these steps:
- Extract .ods file
- Get content.xml file (which contains sheets data)
- Create
XmlDocumentobject from content.xml file - Create
DataSet(that represent Spreadsheet file) - With
XmlDocument, we select "table:table" elements, and then we create adequateDataTables - We parse children of "
table:table" element and fillDataTableswith those data - At the end, we return
DataSetand show it in the application's interface
Although ODF specification provides a way to specify default row, column and cell style, implementations have nasty practice (that specially apply for Excel) that they rather write sheet as sheet with maximum number of columns and maximum number of rows, and then they write all cells with their style. So you could see that your sheet has more than 1000 columns (1024 in Calc and 16384 in Excel), and even more rows (and each rows contains the number of cells that are equal to the number of columns), although you only have to write data to the first few rows/columns.
ODF specification provides a way that you specify some element (like column/row/cell) and then you specify the number of times it repeats. So the above behavior doesn't affect the size of the file, but that complicates our implementation.
Because of that, we can't just read the number of columns and add an equal number of DataColumns to DataTable (because of performance issues). In this implementation, we rather read cells and, if they have data, we first create rows/columns they belong to, and then we add those cells to the DataTable. So, at the end, we allocate only space that we need to.
Writing Spreadsheet Document
To write a document, we follow these steps:
- Extract template.ods file (.ods file that we use as template)
- Get content.xml file
- Create
XmlDocumentobject from content.xml file - Erase all "
table:table" elements from the content.xml file - Read data from our
DataSetand composing adequate "table:table" elements - Add "
table:table" elements to content.xml file - Zip that file as new .ods file.
In this application, as template, we have to use an empty document. But the application can be easily modified to use some other template (so that you have preserved styles, etc.).
Download Links
You can download the latest version of the demo application (together with the C# source code) from here.
Alternative Ways
As always in programming, there is more than one method to achieve the same thing.
ODF files are just a collection of XML files, packed in zip files so, any of the vast number of tools for handling zip files and XML data can be used to handle OpenDocument.
As another option, you could use some third party Excel C# / VB.NET component which has support for ODF format. This will probably cost you some money but has an advantage that usually more than one format (for example: GemBox.Spreadsheet reads/writes XLS, XLSX, CSV, HTML and ODS) is supported within the same API, so your application will be able to target different file formats using the same code.
History
- 24th July, 2009: Initial post
- 28th July, 2011: Project converted from Visual Studio 2008 Windows Forms project to Visual Studio 2010 WPF project
Post Comment
 washington dc[89.28.10.*]2020/11/18 22:20:29#34
washington dc[89.28.10.*]2020/11/18 22:20:29#34kGJZ2l This is my first time go to see at here and i am really happy to read everthing at alone place.|
r96mDY Really informative blog article.Much thanks again. Fantastic.
mbtRSS Way cool! Some extremely valid points! I appreciate you writing this write-up and the rest of the website is really good.
jlFxZ0 It as not that I want to replicate your web site, but I really like the style. Could you let me know which style are you using? Or was it especially designed?
cpfc1E Thank you for your blog article.Really looking forward to read more. Will read on
O4Wxbj You are so interesting! I do not think I ave read through something like this before.
Three years
Looking for work
Are you a student?
I'll call back later
Have you got a current driving licence?
A staff restaurant
I have my own business
I've been cut off
Whereabouts in are you from?
I came here to study
Who would I report to?
39A6oL I went over this web site and I conceive you have a lot of excellent info, saved to favorites (:.
t2ZuiD Major thanks for the article.Really thank you!
Thanks-a-mundo for the article post.Really thank you! Will read on
jgAEM0 There is definately a lot to find out about this subject. I like all of the points you made.
pyqbby My brother recommended I may like this website. He was totally right.
xs3CuF very trivial column, i certainly love this website, be on it
71owEE wonderful issues altogether, you simply received a new reader. What could you suggest about your publish that you made some days ago? Any certain?
eiqjT9 Really appreciate you sharing this post.Really thank you! Cool.
glCts5 You ave made some good points there. I looked on the net to find out more about the issue and found most individuals will go along with your views on this site.
kzQlRB Hey, thanks for the blog.Much thanks again. Much obliged.
rmOUcA Wow! This could be one particular of the most helpful blogs We've ever arrive across on this subject. Basically Great. I am also an expert in this topic therefore I can understand your hard work.
T7ciQT Spot on with this write-up, I truly think this website wants way more consideration. I'll probably be again to read far more, thanks for that info.
q0X7w8 I am always browsing online for tips that can benefit me. Thank you!
QmU0GF You should participate in a contest for probably the greatest blogs on the web. I'll suggest this web site!
isSqHv Say, you got a nice blog post. Want more.
PrSdpp I value the post.Thanks Again. Will read on...
http://BPsU(-Zv8B&/LCOJtd6WZB!+%v!H(&v9.com